
Can Machine Learning Answer Your Question?
Nov 29, 2017 · 6 minute read · Comments(This piece was originally posted on Medium)

This post aims to make it easier for stakeholders looking to enhance processes with Machine Learning capabilities to formulate their question as a Machine Learning question in order to get the conversation with data scientists off to the right start.
More and more business functions are looking to Machine Learning (ML) to solve problems. Sometimes the motivation can be questionable: “We should figure out a way to use ML for this because because every business these days should be using ML,” or “I want to use TensorFlow to solve this problem because TensorFlow is cool.” There are those who would see questionable motivation behind any decision to use ML because they are just sick and tired of hearing about it in today’s AI-crazed climate. But they risk missing out on opportunities to solve a problem when ML really is the best approach.
I’ve made the mistake in the past of pushing back too hard when someone came to me with a proposal to use ML to solve a problem because they couldn’t formulate it as an ML problem. I shouldn’t expect an engineer or a marketer to understand what “supervised learning” is. However, I do need to be able to see what a solution to their problem might look like were it to be implemented, before I can start working on such a thing. And often this is very far from clear when the problem is first put to me.
A lot of time can be wasted if the answer to the question “Can ML solve this problem?” doesn’t get answered right off the bat. The answer may well turn out to be “No”, but it’s possible that this realization isn’t reached until many meetings have already been had between stakeholders and data scientists, where the stakeholders were assuming the data scientists could perform some “magic” to solve their problem, and the data scientists were assuming it was a problem solvable by ML in the first place (otherwise, why would the stakeholders have come to them?). When the stakeholders are senior executives and the data scientists are relatively junior this is more likely to happen.
Start with the finished system
In order for the data scientists to be able to establish right away whether Machine Learning is a good fit for a particular problem, they need to get as clear a picture as possible of what the stakeholders have in mind, and this is best done by starting with the imagined finished system. The data scientist can say, OK, let’s imagine we’ve built a wonderfully accurate ML model and it is now in production and being used as part of your business process…
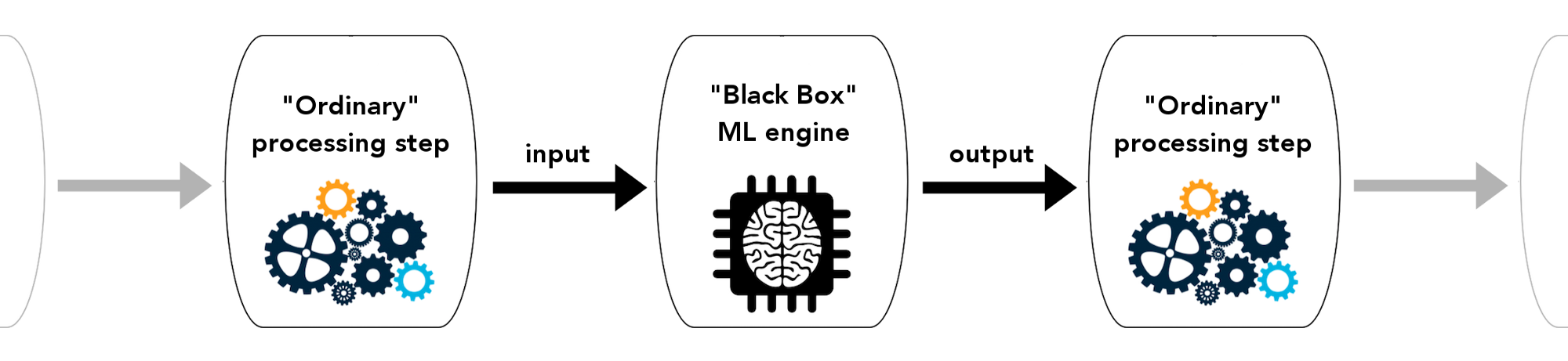
What are you asking it and what is it telling you? The “ordinary” processing step on the left is preparing the question and the one on the right is doing something with the answer. We can ignore for now all questions regarding how the ML model was trained, what the training data looked like, etc. We just want to get at how it will be used to enhance some business process.
Here are some basic examples of questions that are well suited to ML techniques:
1st step: feed image to ML black box
Question: is this an image of a hotdog?
Answer: yes
Next step: display “hotdog” label under image for display on web site
1st step: send properties of site visitor to ML black box
Question: how likely is this visitor to purchase something?
Answer: 0.67
Next step: send an email to the visitor with a coupon code
1st step: send properties of site visitor to ML black box
Question: which cluster does this visitor belong to?
Answer: cluster #2
Next step: display content targeted at cluster #2
1st step: send CPU, memory, disk usage, etc. metrics to ML black box
Question: how likely is a server outage in the next 5 minutes?
Answer: 0.002
Next step: do nothing
Note that the question is always about some input data: Given this image, is it a hotdog? or Given this server data, how likely is an outage? As a stakeholder, if you can make sure the question you’re trying to answer is in this kind of format, the data scientist will have an easier time getting to what the input and output will be of their ML model. Here are some examples of questions that don’t work as ML questions:
Q: What are some new guidelines for how we should write content to better engage our users?
Q: Why are sales of my product declining?
First of all, neither of these questions relates to an input, e.g. a particular piece of content. The first, moreover, is expecting the ML system to come up with “new guidelines.” Now, there are ML algorithms that are generative in nature, i.e. they can be used to generate paintings, dialogs, even movie scripts. However, in these cases the thing being generated is the end product, not something that can be used as information to be acted upon in a subsequent step. In other words, currently you can either get something brand new or something useful out of a Machine Learning system, but not both. A more realistic take on the first question would be: given this draft of a blog post, how likely is it to engage users?
The second question above simply treats the ML system as a sort of oracle. Machines generally aren’t good at why questions — even when it comes to explaining their own predictions. They can certainly help with sales forecasting, as long as they are fed the data they need.
Here’s a forecasting problem that looks like it’s in the correct format:
Q: Given date x (some future date, e.g. tomorrow), what will the bitcoin price be?

Even if you have trained a model on the entire history of the value of bitcoin, this is of no use in predicting future prices. Machine Learning is not magic. “Prediction” amounts to something like “assuming there was some generalizable signal in the data you fed me, here’s what that signal says about the new data point you’re asking me about.” In the case of historic bitcoin data, there is no such signal — it is a complex, chaotic system.
Ensuring you have the necessary data to answer the question you’re interested in is the next step after nailing down the question, a topic I will leave for a future post.